Abstract
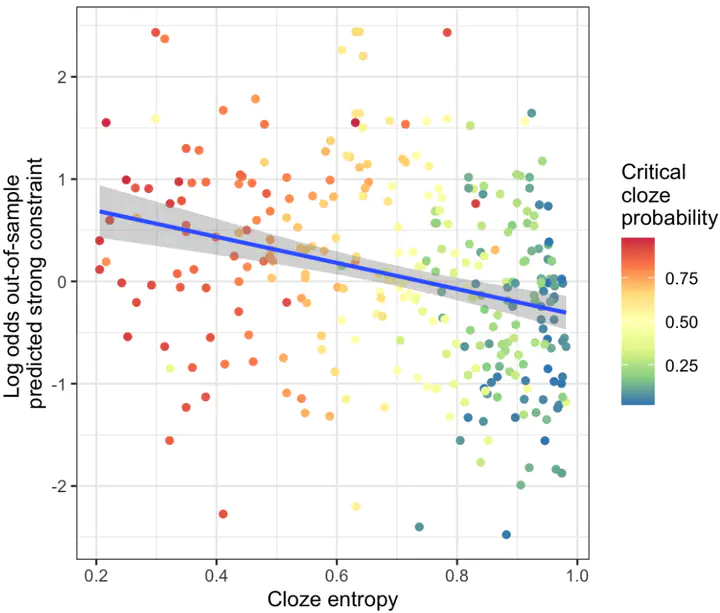
In two experiments we have tested how much context on its own – without knowledge of the final word – can directly encode the predictability of upcoming linguistic information. In contrast to prior work focusing on surprisal, this work leverages experimenter-defined labels (sentential constraint categories) and sentence embeddings derived from the LLM RoBERTa and shows that the model’s hidden states directly encode uncertainty about upcoming information. We demonstrated that we are able to train classifiers that can predict the categorical constraint of a sentence and that the model’s certainty about the constraint category correlates with the cloze probability of the target word and relatedly the entropy of participants’ responses.
Type
Publication
Proceedings of the Society for Computation in Linguistics, 5(1), 225-228